Activation Map Editor
In short, this is an experiment in finding new ways of interacting with generative machine learning models. It is a tool which exposes the inner workings of a Convolutional Neural Network and allows you to edit the intermediary activation maps and re-run the model to observe how this affects the output.
Try clicking on a slice of an activation map below to open up the editor. Once you have made a change close the editor and clicking Run in the sidebar to run the model.
Machine learning models are often considered black boxes - abstract entities which have internal processes which can often only be understood by observing the output relative to a given input.
Machine learning papers often try to address this with large block diagrams which represent the inner workings of the model. The diagrams aim to join the dots from input to output showing the reader how data is transformed from start to finish. For example see the the diagram used in Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks , the original DCGAN paper by Radford et al.
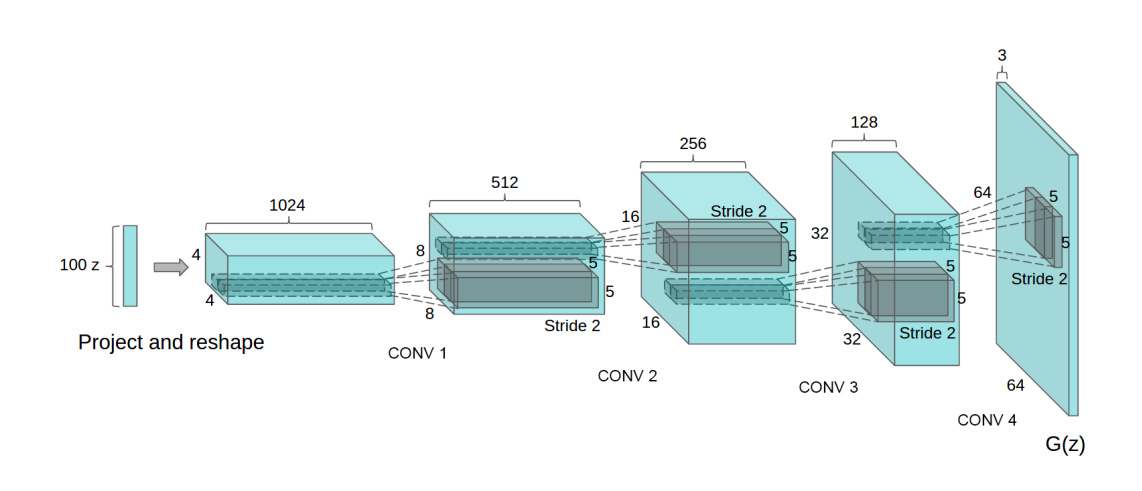 Source
SourceThe diagram above does successfully describe the transformation of data through the model (with the accompanying description in the paper). Below I have annoted the diagram to fill you in.
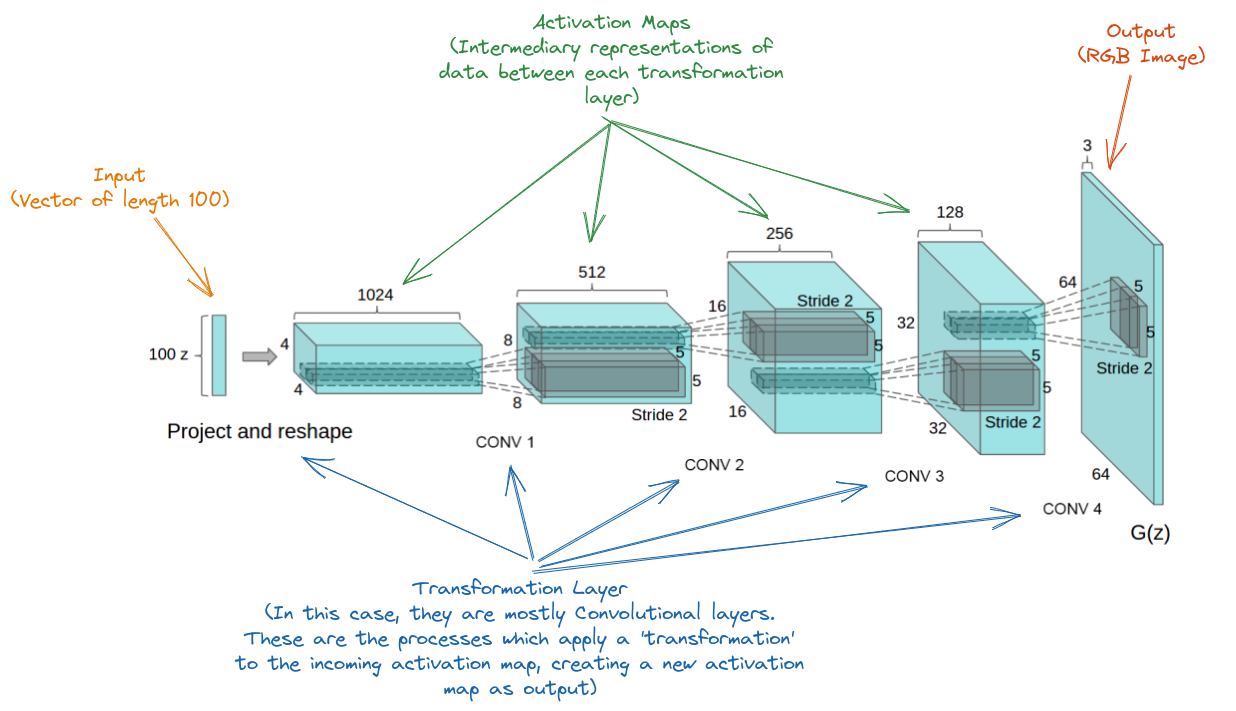
These diagrams are immensely useful in understanding the overall shape of the model, particularly if you aim to reproduce the model or expand upon the model. But more often than not they just illustrate all the data which is generally considered off limits. The output of the model is often the most interesting part of the model, but what if we could manipulate the inner-representations of the model as well? How would this affect the output? The weights are stored in the transformation layers and remain frozen (for now), but what if we could reach in and mess around with the data as it moves through the model?
That's what this demo aims to do. It gives you access the the activation maps stored within the model and allows you to pull out a slice to edit it as you would like. You can draw on it by clicking, holding shift darkens; you can fill the slice with a colour; rotate it; scale it and you can apply these edits to the whole activation map if you want.
Initially you might not get exciting results, but the effects you have are very different if the changes are made near the input of the model as opposed to the output. In the early layers of a model like this the changes are quite high level. By these we mean larger more abstract concepts are put in place, like the size and shape of the face, the large colour groups, the postion of the face and so on. Whereas the later layers generally make impacts and a lower level. This can be thought of as getting closer to pixel level where changes are very local and may just affect subtle patterns found in the hair for example.
This idea was originally called Network Bending and it is a process developed by Broad, Leymarie and Grierson in Network Bending: Expressive Manipulation of Deep Generative Models. The authors take the same approach in that they make transformations to the activation maps within a generative model, but make the changes in a more programmatic way. The effect on the model is fascinating however as the model in question (StyleGAN2) is much larger than the one used here.
 Source
SourceThis demo works as a proof of concept and it only provides mechanisms for visualising convolutional layers. The modular nature of model architectures means that it is possible to extend this to work with other layers. A simple next step would be to at least show the input vector - the ability to tweak the values of the input might help the user find a starting point they like before manipulating. It would also be interesting to explore more abstract models which do not necessarily produce a representation we understand (such as a face), but more abstract imagery. Manipulating data, or drawing, in a high-level space as opposed to pixel-space, such as the lower layers of a model, is quite an exciting prospect for creating new artistic tools.